Hadoop2.2.0NNHA详细配置+Client透明性试验
引言:前面转载过一篇团队兄弟【伊利丹】写的NNHA实验记录,我也基于他的环境实验了NNHA对于Client的透明性。本篇文...
引言: 前面转载过一篇团队兄弟【伊利丹】写的NN HA实验记录,我也基于他的环境实验了NN HA对于Client的透明性。 本篇文章记录的是亲自配置NN HA的详细全过程,以及全面测试HA对客户端访问透明性的全过程,希望对大家有帮助。
实验环境: Hadoop2.2.0的4节点集群,ZK节点3个(ZK节点数最好为奇数个),hosts文件和各节点角色分配如下:
hosts: 192.168.66.91 master 192.168.66.92 slave1 192.168.66.93 slave2 192.168.66.94 slave3
角色分配: Active NN Standby NN DN JournalNode Zookeeper FailoverController
master V V V V
slave1 V V V V V
slave2 V V V
slave3 V
实验过程: 1.下载稳定版Zookeeper 并解压到hadoop集群某目录下,我放在了/home/yarn/下。 2.修改配置文件 配置文件在conf文件夹中,将zoo_sample.cfg改名为zoo.cfg,并对其做响应修改,以下是修改过后的zoo.cfg # The number of milliseconds of each tick ZK之间,或者Client和ZK之间心跳的时间间隔 tickTime=2000
# The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5
# the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. 保存ZK数据的目录,请自行创建后在此处指定 dataDir=/home/yarn/Zookeeper/zoodata
# the port at which the clients will connect 客户端连接ZK服务器的端口 clientPort=2181
# the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # #sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
#保存ZK日志的目录,请自行创建后在此处指定 dataLogDir=/home/yarn/Zookeeper/zoolog
#******以下部分均为分布式ZK集群使用****** #ZK集群初始化时,Follower节点需要和Leader节点通信,initLimit配置的是Leader最多等待多少个心跳 initLimit=5
#Leader和Follower之间发送消息、请求和应答时,最多等待多少个心跳 syncLimit=2
#server.A=B:C:D #A是一个数字,表示这是第几号服务器 #B是当前服务器的ID或者主机名 #C是Follower服务器与Leader服务器交换信息的端口 #D是当Leader挂掉时,重新选举Leader所使用的端口 server.1=192.168.66.91:2888:3888 server.2=192.168.66.92:2888:3888 server.3=192.168.66.93:2888:3888 #千万注意:接下来需要在各个几点的dataDir目录下建立myid文件,内容就是相应的A,也就是说,各个ZK节点的myid文件内容不同 !!! 3.修改各个节点的环境变量 在/etc/profile文件添加: export ZOOKEEPER_HOME=/home/yarn/Zookeeper/zookeeper-3.4.6 并为PATH加上 $ZOOKEEPER_HOME/bin 注意:export ZOOKEEPER_HOME要在PATH的上方。 下面开始修改Hadoop的配置文件: 4.修改core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://myhadoop</value> <description>注意:myhadoop为集群的逻辑名,需与hdfs-site.xml中的dfs.nameservices一致!</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/yarn/Hadoop/hdfs2.0/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> <description>各个ZK节点的IP/host,及客户端连接ZK的端口,该端口需与zoo.cfg中的clientPort一致!</description> </property> </configuration> 5.修改hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href=http://www.it165.net/admin/html/201406/"configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
<configuration> <property> <name>dfs.nameservices</name> <value>myhadoop</value> <description> Comma-separated list of nameservices. as same as fs.defaultFS in core-site.xml. </description> </property>
<property> <name>dfs.ha.namenodes.myhadoop</name> <value>nn1,nn2</value> <description> The prefix for a given nameservice, contains a comma-separated list of namenodes for a given nameservice (eg EXAMPLENAMESERVICE). </description> </property>
<property> <name>dfs.namenode.rpc-address.myhadoop.nn1</name> <value>master:8020</value> <description> RPC address for nomenode1 of hadoop-test </description> </property>
<property> <name>dfs.namenode.rpc-address.myhadoop.nn2</name> <value>slave1:8020</value> <description> RPC address for nomenode2 of hadoop-test </description> </property>
<property> <name>dfs.namenode.http-address.myhadoop.nn1</name> <value>master:50070</value> <description> The address and the base port where the dfs namenode1 web ui will listen on. </description> </property>
<property> <name>dfs.namenode.http-address.myhadoop.nn2</name> <value>slave1:50070</value> <description> The address and the base port where the dfs namenode2 web ui will listen on. </description> </property>
<property> <name>dfs.namenode.servicerpc-address.myhadoop.n1</name> <value>master:53310</value> </property> <property> <name>dfs.namenode.servicerpc-address.myhadoop.n2</name> <value>slave1:53310</value> </property>
<property> <name>dfs.namenode.name.dir</name> <value>file:///home/yarn/Hadoop/hdfs2.0/name</value> <description>Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. </description> </property>
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave1:8485;slave2:8485;slave3:8485/hadoop-journal</value> <description>A directory on shared storage between the multiple namenodes in an HA cluster. This directory will be written by the active and read by the standby in order to keep the namespaces synchronized. This directory does not need to be listed in dfs.namenode.edits.dir above. It should be left empty in a non-HA cluster. </description> </property>
<property> <name>dfs.datanode.data.dir</name> <value>file:///home/yarn/Hadoop/hdfs2.0/data</value> <description>Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored. </description> </property>
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> <description> Whether automatic failover is enabled. See the HDFS High Availability documentation for details on automatic HA configuration. </description> </property>
<property> <name>dfs.journalnode.edits.dir</name> <value>/home/yarn/Hadoop/hdfs2.0/journal/</value> </property>
<property> <name>dfs.client.failover.proxy.provider.myhadoop</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> <description>Configure the name of the Java class which will be used by the DFS Client to determine which NameNode is the current Active, and therefore which NameNode is currently serving client requests. 这个类是Client的访问代理,是HA特性对于Client透明的关键! </description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> <description>how to communicate in the switch process</description> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/yarn/.ssh/id_rsa</value> <description>the location stored ssh key</description> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>1000</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>8</value> </property>
</configuration> 6.将修改好的core-site.xml和hdfs-site.xml拷贝到各个hadoop节点。 7.启动 (1)启动ZK 在所有的ZK节点执行命令: zkServer.sh start
查看各个ZK的从属关系: yarn@master:~$ zkServer.sh status JMX enabled by default Using config: /home/yarn/Zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: follower
yarn@slave1:~$ zkServer.sh status JMX enabled by default Using config: /home/yarn/Zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: follower
yarn@slave2:~$ zkServer.sh status JMX enabled by default Using config: /home/yarn/Zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: leader
注意: 哪个ZK节点会成为leader是随机的,第一次实验时slave2成为了leader,第二次实验时slave1成为了leader!
此时,在各个节点都可以查看到ZK进程: yarn@master:~$ jps 3084 QuorumPeerMain 3212 Jps
(2)格式化ZK(仅第一次需要做) 任意ZK节点上执行: hdfs zkfc -formatZK
(3)启动ZKFC ZookeeperFailoverController是用来监控NN状态,协助实现主备NN切换的,所以仅仅在主备NN节点上启动就行: hadoop-daemon.sh start zkfc
启动后我们可以看到ZKFC进程: yarn@master:~$ jps 3084 QuorumPeerMain 3292 Jps 3247 DFSZKFailoverController
(4)启动用于主备NN之间同步元数据信息的共享存储系统JournalNode 参见角色分配表,在各个JN节点上启动: hadoop-daemon.sh start journalnode
启动后在各个JN节点都可以看到JournalNode进程: yarn@master:~$ jps 3084 QuorumPeerMain 3358 Jps 3325 JournalNode 3247 DFSZKFailoverController
(5)启动主NN 注意:这里没做HDFS的格式化,默认为已经格式化。 在主NN节点执行命令启动NN: hadoop-daemon.sh start namenode
启动后可以看到NN进程: yarn@master:~$ jps 3084 QuorumPeerMain 3480 Jps 3325 JournalNode 3411 NameNode 3247 DFSZKFailoverController
(6)在备NN上同步主NN的元数据信息 hdfs namenode -bootstrapStandby
以下是正常执行时的最后部分日志: Re-format filesystem in Storage Directory /home/yarn/Hadoop/hdfs2.0/name ? (Y or N) Y 14/06/15 10:09:08 INFO common.Storage: Storage directory /home/yarn/Hadoop/hdfs2.0/name has been successfully formatted. 14/06/15 10:09:09 INFO namenode.TransferFsImage: Opening connection to :50070/getimage?getimage=1&txid=935&storageInfo=-47:564636372:0:CID-d899b10e-10c9-4851-b60d-3e158e322a62 14/06/15 10:09:09 INFO namenode.TransferFsImage: Transfer took 0.11s at 63.64 KB/s 14/06/15 10:09:09 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000935 size 7545 bytes. 14/06/15 10:09:09 INFO util.ExitUtil: Exiting with status 0 14/06/15 10:09:09 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at slave1/192.168.66.92 ************************************************************/
(7)启动备NN 在备NN上执行命令: hadoop-daemon.sh start namenode
(8)设置主NN(这一步可以省略,这是在设置手动切换NN时的步骤,ZK已经自动选择一个节点作为主NN了) 到目前为止,其实HDFS还不知道谁是主NN,可以通过监控页面查看,两个节点的NN都是Standby状态。 下面我们需要在主NN节点上执行命令激活主NN: hdfs haadmin -transitionToActive nn1
(9)在主NN上启动Datanode 在[nn1]上,启动所有datanode hadoop-daemons.sh start datanode 8.效果验证1--主备自动切换 目前的主NN是192.168.0.91
备NN是192.168.0.92
我在主NN上kill掉NameNode进程: yarn@master:~$ jps 5161 NameNode 5085 JournalNode 5438 Jps 4987 DFSZKFailoverController 4904 QuorumPeerMain yarn@master:~$ kill 5161 yarn@master:~$ jps 5451 Jps 5085 JournalNode 4987 DFSZKFailoverController 4904 QuorumPeerMain
此时,主NN监控页面无法访问:
备NN自动切换为主NN:
9.效果验证2--HA对shell的透明性 访问逻辑名myhadoop,执行命令查看目录结构,不受影响: yarn@slave3:~$ hadoop dfs -ls hdfs://myhadoop/ DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it.
Found 3 items drwxr-xr-x - yarn supergroup 0 2014-03-20 00:10 hdfs://myhadoop/home drwxrwx--- - yarn supergroup 0 2014-03-17 20:11 hdfs://myhadoop/tmp drwxr-xr-x - yarn supergroup 0 2014-03-17 20:15 hdfs://myhadoop/workspace 10.效果验证3--HA对Client程序的透明性 使用自己写的HdfsDAO.java测试,程序中将指向HDFS的path设置为: private static final String HDFS = "hdfs://myhadoop/"; 先ping myhadoop确保没有配置hosts,然后运行程序,一切正常: yarn@master:~$ ping myhadoop ping: unknown host myhadoop yarn@master:~$ hadoop jar Desktop/hatest.jar HdfsDAO ls: / ========================================================== name: hdfs://myhadoop/home, folder: true, size: 0 name: hdfs://myhadoop/tmp, folder: true, size: 0 name: hdfs://myhadoop/workspace, folder: true, size: 0 ==========================================================
hosts: 192.168.66.91 master 192.168.66.92 slave1 192.168.66.93 slave2 192.168.66.94 slave3
角色分配: Active NN Standby NN DN JournalNode Zookeeper FailoverController
master V V V V
slave1 V V V V V
slave2 V V V
slave3 V
实验过程: 1.下载稳定版Zookeeper 并解压到hadoop集群某目录下,我放在了/home/yarn/下。 2.修改配置文件 配置文件在conf文件夹中,将zoo_sample.cfg改名为zoo.cfg,并对其做响应修改,以下是修改过后的zoo.cfg # The number of milliseconds of each tick ZK之间,或者Client和ZK之间心跳的时间间隔 tickTime=2000
# The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5
# the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. 保存ZK数据的目录,请自行创建后在此处指定 dataDir=/home/yarn/Zookeeper/zoodata
# the port at which the clients will connect 客户端连接ZK服务器的端口 clientPort=2181
# the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # #sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
#保存ZK日志的目录,请自行创建后在此处指定 dataLogDir=/home/yarn/Zookeeper/zoolog
#******以下部分均为分布式ZK集群使用****** #ZK集群初始化时,Follower节点需要和Leader节点通信,initLimit配置的是Leader最多等待多少个心跳 initLimit=5
#Leader和Follower之间发送消息、请求和应答时,最多等待多少个心跳 syncLimit=2
#server.A=B:C:D #A是一个数字,表示这是第几号服务器 #B是当前服务器的ID或者主机名 #C是Follower服务器与Leader服务器交换信息的端口 #D是当Leader挂掉时,重新选举Leader所使用的端口 server.1=192.168.66.91:2888:3888 server.2=192.168.66.92:2888:3888 server.3=192.168.66.93:2888:3888 #千万注意:接下来需要在各个几点的dataDir目录下建立myid文件,内容就是相应的A,也就是说,各个ZK节点的myid文件内容不同 !!! 3.修改各个节点的环境变量 在/etc/profile文件添加: export ZOOKEEPER_HOME=/home/yarn/Zookeeper/zookeeper-3.4.6 并为PATH加上 $ZOOKEEPER_HOME/bin 注意:export ZOOKEEPER_HOME要在PATH的上方。 下面开始修改Hadoop的配置文件: 4.修改core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://myhadoop</value> <description>注意:myhadoop为集群的逻辑名,需与hdfs-site.xml中的dfs.nameservices一致!</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/yarn/Hadoop/hdfs2.0/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> <description>各个ZK节点的IP/host,及客户端连接ZK的端口,该端口需与zoo.cfg中的clientPort一致!</description> </property> </configuration> 5.修改hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href=http://www.it165.net/admin/html/201406/"configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
<configuration> <property> <name>dfs.nameservices</name> <value>myhadoop</value> <description> Comma-separated list of nameservices. as same as fs.defaultFS in core-site.xml. </description> </property>
<property> <name>dfs.ha.namenodes.myhadoop</name> <value>nn1,nn2</value> <description> The prefix for a given nameservice, contains a comma-separated list of namenodes for a given nameservice (eg EXAMPLENAMESERVICE). </description> </property>
<property> <name>dfs.namenode.rpc-address.myhadoop.nn1</name> <value>master:8020</value> <description> RPC address for nomenode1 of hadoop-test </description> </property>
<property> <name>dfs.namenode.rpc-address.myhadoop.nn2</name> <value>slave1:8020</value> <description> RPC address for nomenode2 of hadoop-test </description> </property>
<property> <name>dfs.namenode.http-address.myhadoop.nn1</name> <value>master:50070</value> <description> The address and the base port where the dfs namenode1 web ui will listen on. </description> </property>
<property> <name>dfs.namenode.http-address.myhadoop.nn2</name> <value>slave1:50070</value> <description> The address and the base port where the dfs namenode2 web ui will listen on. </description> </property>
<property> <name>dfs.namenode.servicerpc-address.myhadoop.n1</name> <value>master:53310</value> </property> <property> <name>dfs.namenode.servicerpc-address.myhadoop.n2</name> <value>slave1:53310</value> </property>
<property> <name>dfs.namenode.name.dir</name> <value>file:///home/yarn/Hadoop/hdfs2.0/name</value> <description>Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. </description> </property>
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave1:8485;slave2:8485;slave3:8485/hadoop-journal</value> <description>A directory on shared storage between the multiple namenodes in an HA cluster. This directory will be written by the active and read by the standby in order to keep the namespaces synchronized. This directory does not need to be listed in dfs.namenode.edits.dir above. It should be left empty in a non-HA cluster. </description> </property>
<property> <name>dfs.datanode.data.dir</name> <value>file:///home/yarn/Hadoop/hdfs2.0/data</value> <description>Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored. </description> </property>
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> <description> Whether automatic failover is enabled. See the HDFS High Availability documentation for details on automatic HA configuration. </description> </property>
<property> <name>dfs.journalnode.edits.dir</name> <value>/home/yarn/Hadoop/hdfs2.0/journal/</value> </property>
<property> <name>dfs.client.failover.proxy.provider.myhadoop</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> <description>Configure the name of the Java class which will be used by the DFS Client to determine which NameNode is the current Active, and therefore which NameNode is currently serving client requests. 这个类是Client的访问代理,是HA特性对于Client透明的关键! </description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> <description>how to communicate in the switch process</description> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/yarn/.ssh/id_rsa</value> <description>the location stored ssh key</description> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>1000</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>8</value> </property>
</configuration> 6.将修改好的core-site.xml和hdfs-site.xml拷贝到各个hadoop节点。 7.启动 (1)启动ZK 在所有的ZK节点执行命令: zkServer.sh start
查看各个ZK的从属关系: yarn@master:~$ zkServer.sh status JMX enabled by default Using config: /home/yarn/Zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: follower
yarn@slave1:~$ zkServer.sh status JMX enabled by default Using config: /home/yarn/Zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: follower
yarn@slave2:~$ zkServer.sh status JMX enabled by default Using config: /home/yarn/Zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: leader
注意: 哪个ZK节点会成为leader是随机的,第一次实验时slave2成为了leader,第二次实验时slave1成为了leader!
此时,在各个节点都可以查看到ZK进程: yarn@master:~$ jps 3084 QuorumPeerMain 3212 Jps
(2)格式化ZK(仅第一次需要做) 任意ZK节点上执行: hdfs zkfc -formatZK
(3)启动ZKFC ZookeeperFailoverController是用来监控NN状态,协助实现主备NN切换的,所以仅仅在主备NN节点上启动就行: hadoop-daemon.sh start zkfc
启动后我们可以看到ZKFC进程: yarn@master:~$ jps 3084 QuorumPeerMain 3292 Jps 3247 DFSZKFailoverController
(4)启动用于主备NN之间同步元数据信息的共享存储系统JournalNode 参见角色分配表,在各个JN节点上启动: hadoop-daemon.sh start journalnode
启动后在各个JN节点都可以看到JournalNode进程: yarn@master:~$ jps 3084 QuorumPeerMain 3358 Jps 3325 JournalNode 3247 DFSZKFailoverController
(5)启动主NN 注意:这里没做HDFS的格式化,默认为已经格式化。 在主NN节点执行命令启动NN: hadoop-daemon.sh start namenode
启动后可以看到NN进程: yarn@master:~$ jps 3084 QuorumPeerMain 3480 Jps 3325 JournalNode 3411 NameNode 3247 DFSZKFailoverController
(6)在备NN上同步主NN的元数据信息 hdfs namenode -bootstrapStandby
以下是正常执行时的最后部分日志: Re-format filesystem in Storage Directory /home/yarn/Hadoop/hdfs2.0/name ? (Y or N) Y 14/06/15 10:09:08 INFO common.Storage: Storage directory /home/yarn/Hadoop/hdfs2.0/name has been successfully formatted. 14/06/15 10:09:09 INFO namenode.TransferFsImage: Opening connection to :50070/getimage?getimage=1&txid=935&storageInfo=-47:564636372:0:CID-d899b10e-10c9-4851-b60d-3e158e322a62 14/06/15 10:09:09 INFO namenode.TransferFsImage: Transfer took 0.11s at 63.64 KB/s 14/06/15 10:09:09 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000935 size 7545 bytes. 14/06/15 10:09:09 INFO util.ExitUtil: Exiting with status 0 14/06/15 10:09:09 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at slave1/192.168.66.92 ************************************************************/
(7)启动备NN 在备NN上执行命令: hadoop-daemon.sh start namenode
(8)设置主NN(这一步可以省略,这是在设置手动切换NN时的步骤,ZK已经自动选择一个节点作为主NN了) 到目前为止,其实HDFS还不知道谁是主NN,可以通过监控页面查看,两个节点的NN都是Standby状态。 下面我们需要在主NN节点上执行命令激活主NN: hdfs haadmin -transitionToActive nn1
(9)在主NN上启动Datanode 在[nn1]上,启动所有datanode hadoop-daemons.sh start datanode 8.效果验证1--主备自动切换 目前的主NN是192.168.0.91

备NN是192.168.0.92

我在主NN上kill掉NameNode进程: yarn@master:~$ jps 5161 NameNode 5085 JournalNode 5438 Jps 4987 DFSZKFailoverController 4904 QuorumPeerMain yarn@master:~$ kill 5161 yarn@master:~$ jps 5451 Jps 5085 JournalNode 4987 DFSZKFailoverController 4904 QuorumPeerMain
此时,主NN监控页面无法访问:

备NN自动切换为主NN:

9.效果验证2--HA对shell的透明性 访问逻辑名myhadoop,执行命令查看目录结构,不受影响: yarn@slave3:~$ hadoop dfs -ls hdfs://myhadoop/ DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it.
Found 3 items drwxr-xr-x - yarn supergroup 0 2014-03-20 00:10 hdfs://myhadoop/home drwxrwx--- - yarn supergroup 0 2014-03-17 20:11 hdfs://myhadoop/tmp drwxr-xr-x - yarn supergroup 0 2014-03-17 20:15 hdfs://myhadoop/workspace 10.效果验证3--HA对Client程序的透明性 使用自己写的HdfsDAO.java测试,程序中将指向HDFS的path设置为: private static final String HDFS = "hdfs://myhadoop/"; 先ping myhadoop确保没有配置hosts,然后运行程序,一切正常: yarn@master:~$ ping myhadoop ping: unknown host myhadoop yarn@master:~$ hadoop jar Desktop/hatest.jar HdfsDAO ls: / ========================================================== name: hdfs://myhadoop/home, folder: true, size: 0 name: hdfs://myhadoop/tmp, folder: true, size: 0 name: hdfs://myhadoop/workspace, folder: true, size: 0 ==========================================================
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/server/equal/12299.shtml
上一篇:Mongodb集群搭建过程及常见
下一篇:管理votingdisks
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
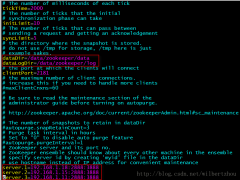 ZooKeeper集群安装
ZooKeeper集群安装
时间:2021-01-10
-
 KeepAlive详解
KeepAlive详解
时间:2021-01-10
-
 Spark教程 构建Spark集群(
Spark教程 构建Spark集群(
时间:2021-01-10
-
 高效搭建Spark完全分布式集
高效搭建Spark完全分布式集
时间:2021-01-10
-
 负载均衡与缓存
负载均衡与缓存
时间:2021-01-10
-
 Hadoop2.2.0NNHA详细配置+Cli
Hadoop2.2.0NNHA详细配置+Cli
时间:2021-01-10
-
 Mongodb集群搭建过程及常见
Mongodb集群搭建过程及常见
时间:2021-01-09
-
 DRBD+HeartBeat架构实验
DRBD+HeartBeat架构实验
时间:2021-01-09
热门文章
-
 Nagios监控生产环境redis集群服务实战
Nagios监控生产环境redis集群服务实战
时间:2021-01-08
-
Spark教程 构建Spark集群(1)
时间:2021-01-10
-
 SqlServer横向扩展负载均衡终极利器SqlSer
SqlServer横向扩展负载均衡终极利器SqlSer
时间:2021-01-08
-
 Kafka集群安装
Kafka集群安装
时间:2021-01-09
-
 WAS集群系列(13):举例WAS集群下ear包部
WAS集群系列(13):举例WAS集群下ear包部
时间:2021-01-08
-
 Memcached基础知识
Memcached基础知识
时间:2021-01-08
-
KeepAlive详解
时间:2021-01-10
-
 WAS集群系列(12):集群搭建:步骤10:通
WAS集群系列(12):集群搭建:步骤10:通
时间:2021-01-08
-
 Cloudera Manager 4.6 安装部署hadoop CDH集群
Cloudera Manager 4.6 安装部署hadoop CDH集群
时间:2021-01-09
-
DRBD+HeartBeat架构实验
时间:2021-01-09